ChinaKnowledge.de -
An Encyclopaedia on Chinese History, Literature and Art
The so-called instant index system is a graphical indexing system of Chinese characters developed by the writer, philosopher and linguist Lin Yutang 林語堂 (1895-1976) and exclusively used in his dictionary Dangdai Han-Ying cidian 當代漢英詞典, published in 1972.
Lin Yutang categorised all characters according to the shape of the upper left and the lower right corners. This system was thought to be easier than the traditional radical system or the four corner system. For this reason he called this system the "instant" index system. This name has no Chinese counterpart and is called shangxiaxing chazifa 上下形檢字法 "character lookup method by upper and lower shape" in Chinese.
The upper part is always the geometrically highest point of the character, the lower part the geometrically lowest part. This rule is important because the user might tend to identify the last brush stroke as the lowest part of the character and the first brush stroke as the highest. The highest point of the characters 中, 光 and 由 is thus 丨, and the lowest part of the characters 我 and 成 is ![]() . The geometrical form has nothing to do with semantic elements of a character.
. The geometrical form has nothing to do with semantic elements of a character.
Lin Yutang identifies 33 different main forms which he calls "letters of the Chinese alphbabet". These can be arranged in ten groups. The shape of the "letters" roughly corresponds to the shape of the Chinese characters for the numbers ten 十, twenty 廿, one 一, four 四, five 五, six 六, seven 七, eight 八 and nine 九, and one group roughly to the character 了. The "letters" accordingly bear the respective number. This number is the first part of the identification code of a character.
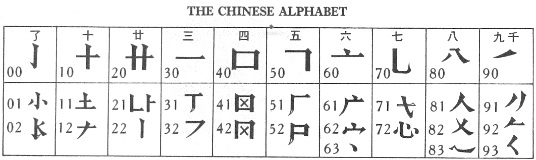 |
The second part of the identification code is a latin letter. The 33 "Chinese letters" only refer to the shape of the upper left corner of the character and are only a crude first orientation. Lin Yutang uses part of the traditional characters to further establish a code for each character. Each "letter" is assigned one or several out of of fifty radicals. The radicals are indicated by a Latin letter. Except the "Chinese letters" 12, 30, 70, 71, 72, 80, 82 and 83 the "letters" are indicated by the Latin letters A, B, C, D or S. If characters are not split (in the table below indicated by "NS") vertically into two parts, no Latin letter is used. For all others, a Latin letter is used for the parts representing a traditional radical.
If the left part of a character does not correspond to a traditional character, the letter S is used. Lin Yutang has reduced the radicals from the traditional 214 to to 50. The radical only counts as radical if it stands on the left side of a character: the 言 in 警 is no "Lin Yutang radical". The combination of the number of the "Chinese letter" (the upper left part of the character) and the latin letter for the traditional radical represents the "Lin Yutang radical". Lin's code of a character begins with this radical. It is separated by a dot from the rest of the code which describes the right part of the character. This part of the code likewise follows the rules for the "Chinese letter".
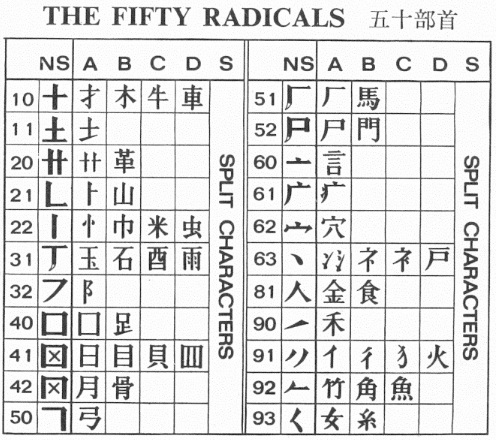 |
The number for the "Chinese letter" in the lower right corner of the character is the first number following after the dot. It is followed by a dash. The dash divides the number of the "Chinese letter" of the lower right part of the character from the number for the "Chinese letter" appearing on the top of that part of the character which remains after subtracting the radical. This is necessary because the number for the lower right corner is not sufficient to identify the character. Too many characters would then have the same code. A similar procedure is necessary for characters in which radicals or graphic elements embrace both the upper left and the lower right corner of the character, like 門, 走, 毛 or 鬼. The characters 栽, 載, 哉, 戴 and 裁 all under the code 11.71.
Some examples might be helpful to have a better understanding of the whole procedure:
| 言 | 60.40 | 60 for 亠 (the upper [left] part) and 40 for 口 (the lower [right] part) |
| 羊 | 80.10 | 80 for 八 (the dots of the upper part) and 10 for 十 (the lower part) |
| 義 | 80.71 | 80 for 八 (the dots of the upper part) and 71 for |
| 詳 | 60A.10 | 60A for the radical 言 (to the left) and 10 for 十 (the lower right corner) |
| 其 | 20.80 | 20 for 艹 (the upper part) and 80 for 八 (the lower part) |
| 基 | 20.11 | 20 for 艹 (the upper part) and 11 for 土 (the lower part) |
| 期 | 20S.42 | 20 for 艹 (the upper left corner), S for a split (non-radical) element to the left, and 42 for 冈 (right part) |
| 楚 | 10.83 | 10 for 十 (the upper left corner) and 83 for 乀 (lower right corner). 10B for 木 can not be used because 木 does not cover the whole left side of the character and is therefore not a radical in Lin's sense. |
| 起 | 11.83-0 | 11 for 土 (upper left corner) and 83 for 乀 (lower right corner) and additional 0 for the hook 乛 of the upper right element |
| 松 | 10B.93 | 10B for 木 (radical to the left) and 93 for the hook ㄑ (lower right corner, the hook going furthest down) |
| 鋁 | 81A.40-4 | 81A for 金 (radical to the left), 40 for 口 (lower right corner) and additional 4 for the upper right 口 |
| 鎔 | 81A.40-6 | 81A for 金 (radical to the left), 40 for 口 (lower right corner) and additional 6 for the upper right 亠 |
| 鎗 | 81A.40-8 | 81A for 金 (radical to the left), 40 for 口 (lower right corner) and additional 8 for the upper right 人 |
| 閩 | 52B.00 | 52 for the radical 門 (to the left), and 00 for the hook 亅 of the inner character 虫 (replacing the lower right corner and the hook going furthest down) |
| 趁 | 11.83-8 | 11 for 土 (upper left corner), 83 for 乀 (lower right corner), and additional 8 for the 八 of the upper right element |
| 載 | 11.71-0 | 11 for 土 (upper left corner) and 71 for |
There are a lot of additional rules for the right attribution of the respective codes to the various calligraphic elements. This is also a problem of the Four Corners Index.